
С агрегирующими функциями в SQL вы знакомы: они возвращают из БД сумму, максимум или среднее арифметическое по определённому полю для всех записей в таблице или для выборки: «SQL, выбери в таблице joke все записи за 1.04.2001 и примени к ним агрегирующую функцию: найди запись с максимальным значением в столбце likes». База данных подсчитает и выведет полученные данные в отдельный столбец результирующей выборки.Для группировки строк используется специальный запрос GROUP BY, в котором перечисляются столбцы, по которым должна идти группировка. Это значит, что если в таблице несколько строк с одним и тем же значением в указанном поле, то такие строки объединятся в одну, а над другими столбцами можно провести групповые операции. Слоноводы несколько дней кормят слонов ивовыми вениками и записывают, кто сколько съел.
| ID | DATE | NAME | BROOM |
|---|---|---|---|
| 1 | 2019-08-17 | Аристарх | 43 |
| 2 | 2019-08-17 | Джульетта | 38 |
| 3 | 2019-08-17 | Кузя | 26 |
| 4 | 2019-08-18 | Аристарх | 35 |
| 5 | 2019-08-18 | Джульетта | 33 |
| 6 | 2019-08-18 | Кузя | 19 |
| 7 | 2019-08-19 | Аристарх | 35 |
| 8 | 2019-08-19 | Джульетта | 41 |
| 9 | 2019-08-19 | Кузя | 9 |
| 10 | 2019-08-20 | Аристарх | 34 |
| 11 | 2019-08-20 | Джульетта | 42 |
| 12 | 2019-08-20 | Кузя | 18 |
| 13 | 2019-08-21 | Аристарх | 44 |
| 14 | 2019-08-21 | Джульетта | 39 |
| 15 | 2019-08-21 | Кузя | 23 |
Затем слоноводы хотят найти для каждого слона день, когда он съел больше всего, и для этого делают запрос к базе.
Ниже приведен запрос, при помощи которого можно получить желаемый результат.
Обратите внимание, что данное решение является особенностью SQLite, и в других СУБД его реализация может отличаться.
SELECT date, name, MAX(broom)
FROM brooms
GROUP BY name; «Под капотом» происходит следующее: сначала в колонке name будут найдены и сгруппированы все совпадающие записи, получится три группы: все записи по Аристарху:
| ID | DATE | NAME | BROOM |
|---|---|---|---|
| 1 | 2019-08-17 | Аристарх | 43 |
| 4 | 2019-08-18 | Аристарх | 35 |
| 7 | 2019-08-19 | Аристарх | 35 |
| 10 | 2019-08-20 | Аристарх | 34 |
| 13 | 2019-08-21 | Аристарх | 44 |
все записи по Джульетте:
| ID | DATE | NAME | BROOM |
|---|---|---|---|
| 2 | 2019-08-17 | Джульетта | 38 |
| 5 | 2019-08-18 | Джульетта | 33 |
| 8 | 2019-08-19 | Джульетта | 41 |
| 11 | 2019-08-20 | Джульетта | 42 |
| 14 | 2019-08-21 | Джульетта | 39 |
и все записи по Кузе:
| ID | DATE | NAME | BROOM |
|---|---|---|---|
| 3 | 2019-08-17 | Кузя | 26 |
| 6 | 2019-08-18 | Кузя | 19 |
| 9 | 2019-08-19 | Кузя | 9 |
| 12 | 2019-08-20 | Кузя | 18 |
| 15 | 2019-08-21 | Кузя | 23 |
Затем функция MAX(broom) в каждой из этих групп найдет максимальное значение в колонке broom, и в результирующую выборку будут выведены имена и найденные значения. Результат запроса будет таким:
| DATE | NAME | MAX(BROOM) |
|---|---|---|
| 2019-08-21 | Аристарх | 44 |
| 2019-08-20 | Джульетта | 42 |
| 2019-08-17 | Кузя | 26 |
Если в БД какого-нибудь магазина в таблице хранятся чеки покупок, можно сгруппировать записи по id покупателя, после чего применить агрегирующую функцию к полю, где указана цена чека — и посчитать максимальную или среднюю сумму заказов определённого покупателя. А можно просто сложить все value по отдельности для A, B и C:
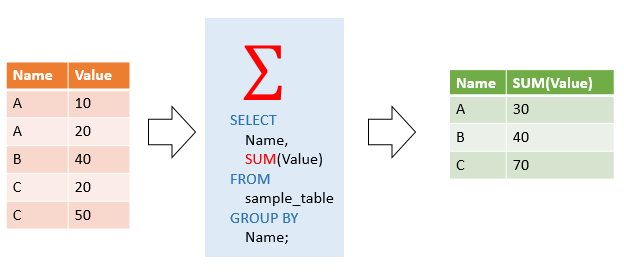
Если не указать GROUP BY — агрегирующая функция будет применена ко всей таблице. Например SELECT SUM(Value) FROM sample_table; вернет значение 140 для примера на иллюстрации, а SELECT MAX(broom) FROM brooms; вернёт 44, максимальное значение во всей колонке broom из таблицы со слонами и вениками.
Метод count()
Задача подсчёта записей в таблице или в выборке столь популярна, что в Django ORM она получила несколько вариантов решения. Чтобы узнать количество полученных строк, можно вызвать методcount() для objects, дописав его к конструкции, делающей выборку:
# выбираем посты, опублибликованные позже (gt) июня 1854 года, затем пересчитываем их
>>> Post.objects.filter(pub_date__month__gt=6, pub_date__year=1854).count()
(0.012) SELECT COUNT(*) AS "__count" FROM "posts_post" WHERE (django_datetime_extract('month', "posts_post"."pub_date", 'UTC') > 6 AND "posts_post"."pub_date" BETWEEN '1854-01-01
00:00:00' AND '1854-12-31 23:59:59.999999'); args=(6, '1854-01-01 00:00:00', '1854-12-31 23:59:59.999999')
30 Когда нужно узнать лишь число записей, но сами записи не нужны — не вызывайте метод all(), применяйте count(). Метод all() заставит базу прочитать и передать в код весь объем данных, а count() выполнит всю работу на стороне базы и вернет лишь одно число. Загрузка и обработка всех данных в такой ситуации — это пустой расход ресурсов.
# Проверка: есть ли данные в таблице
# Неправильный способ: этот код загружает вообще все данные из таблицы
if User.objects.all():
print("Пользователи есть")
# Правильный способ: этот код просит базу вернуть число
if User.objects.count():
print("Пользователи есть") Метод aggregate()
Метод aggregate() применяет агрегирующие функции к определённой выборке или ко всей таблице.В Django есть несколько агрегирующих функций, вот самые популярные из них:
- Avg: вернёт среднее значение по указанной колонке в выборке
- Count: вернёт количество записей в выборке, как и метод
count(), описанный выше - Max: вернёт максимальное значение по указанной колонке в выборке
- Min: вернёт минимальное значение по указанной колонке в выборке
- Sum: вернёт сумму значений по указанной колонке в выборке
Эти функции хранятся в модуле django.db.models, перед применением их надо импортировать в код. Найдём самый большой id и пересчитаем объекты в модели Post при помощи метода aggregate():
>>> from django.db.models import Max, Count
# найти максимальное значение id для объектов Post
>>> Post.objects.aggregate(Max("id"))
(0.000) SELECT MAX("posts_post"."id") AS "id__max" FROM "posts_post"; args=()
{'id__max': 43}
# пересчитать объекты id в модели Post
>>> Post.objects.aggregate(Count("id"))
(0.000) SELECT COUNT("posts_post"."id") AS "id__count" FROM "posts_post"; args=()
{'id__count': 37}
37 Связи между таблицами
При создании модели Post мы добавили в неё ссылку на автора, на модель User, и указали related_name="posts".
class Post(models.Model):
# ... какой-то код
author = models.ForeignKey(
User, on_delete=models.CASCADE, related_name='posts'
) У модели User автоматически появится свойство posts, оно ссылается на все записи текущего автора.
>>> leo = User.objects.get(id=2)
(0.000) SELECT "auth_user"."id", "auth_user"."password", "auth_user"."last_login", "auth_user"."is_superuser", "auth_user"."username", "auth_user"."first_name", "auth_user"."last_name", "auth_user"."email", "auth_user"."is_staff", "auth_user"."is_active", "auth_user"."date_joined" FROM "auth_user" WHERE "auth_user"."id" = 2; args=(2,)
>>> leo.username
'leo'
>>> leo.posts.count()
# leo.posts — это выборка тех объектов из модели Post,
# у которых в поле author_id стоит "2" (которые связаны с leo),
# потому что leo — это объект User с id=2
(0.000) SELECT COUNT(*) AS "__count" FROM "posts_post" WHERE "posts_post"."author_id" = 2; args=(2,)
36 Свойство posts у объекта модели User появилось в результате того, что модель Post ссылается на User. И, благодаря магии ORM, мы можем получить все записи автора, обратившись к свойству posts.Как только вы создаёте в модели поле со ссылкой на другую модель — у второй модели появляется новое свойство, «обратная связь», и к этому свойству можно обращаться, как к любому другому.Свойства, ссылающиеся на объекты, имеют специальный тип: менеджер объектов. До сих пор мы работали с менеджером объектов objects, делая запросы вида User.objects.get(id=2) или Post.objects.all().Свойство posts — такой же менеджер объектов, как и objects, разница лишь в том, что оно было создано при связывании моделей.Для менеджеров объектов можно вызывать метод count(), который пересчитает связанные объекты. Django сам разберется, как правильно составить запрос в этом случае. Чтобы применить агрегирующие функции к связанным данным из других таблиц, запрос делается через аннотирование, методом annotate().
Метод annotate()
Чтобы получить количество записей, созданных каждым пользователем, нужно сгруппировать несколько таблиц и добавить объекту новое свойство, которое будет содержать количество связанных с ним объектов в другой таблице. Конечно, можно было бы в цикле пройтись по всем пользователям, вызывая метод count() менеджера объектов posts. Но это создало бы огромную нагрузку на базу и каскад однотипных запросов. В чистом SQL вопрос решается так: в результирующую выборку попадают запрошенные столбцы исходных таблиц и дополнительные столбцы с результатами вычислений. Похожим образом работает метод annotate() в ORM, но в результате к полученным объектам добавляется новое свойство, содержащее результат вычисления.В следующем примере аргумент posts_count — это имя нового свойства объекта, оно появится у объектов модели User:
# Достать из модели User все объекты,
# создать свойство posts_count и записать в него число постов, связанных с автором.
# posts — это свойство модели User, менеджер объектов
>>>> annotated_results = User.objects.annotate(posts_count = Count('posts'))
>>>
>>> annotated_results
(0.001) SELECT "auth_user"."id", "auth_user"."password", "auth_user"."last_login", "auth_user"."is_superuser", "auth_user"."username", "auth_user"."first_name", "auth_user"."last_name", "auth_user"."email", "auth_user"."is_staff", "auth_user"."is_active", "auth_user"."date_joined", COUNT("posts_post"."id") AS "posts_count" FROM "auth_user" LEFT OUTER JOIN "posts_post" ON ("auth_user"."id" = "posts_post"."author_id") GROUP BY "auth_user"."id", "auth_user"."password", "auth_user"."last_login", "auth_user"."is_superuser", "auth_user"."username", "auth_user"."first_name", "auth_user"."last_name", "auth_user"."email", "auth_user"."is_staff", "auth_user"."is_active", "auth_user"."date_joined" LIMIT 21; args=()
<QuerySet [<User: admin>, <User: leo>]> # перебрать в цикле список пользователей annotated_results
# и для каждого объекта вывести свойство name
# и новое свойство posts_count, которое хранит число постов пользователя
>>> for item in annotated_results:
... print(f'Постов у пользователя {item.username}: {item.posts_count}')
...
(0.000) SELECT "auth_user"."id", "auth_user"."password", "auth_user"."last_login", "auth_user"."is_superuser", "auth_user"."username", "auth_user"."first_name", "auth_user"."last_name", "auth_user"."email", "auth_user"."is_staff", "auth_user"."is_active", "auth_user"."date_joined", COUNT("posts_post"."id") AS "posts_count" FROM "auth_user" LEFT OUTER JOIN "posts_post" ON ("auth_user"."id" = "posts_post"."author_id") GROUP BY "auth_user"."id", "auth_user"."password", "auth_user"."last_login", "auth_user"."is_superuser", "auth_user"."username", "auth_user"."first_name", "auth_user"."last_name", "auth_user"."email", "auth_user"."is_staff", "auth_user"."is_active", "auth_user"."date_joined"; args=()
Постов у пользователя admin: 2
Постов у пользователя leo: 36
# хорошо, что у нас пока что не 100500 авторов Разница между annotate() и aggregate()
Метод annotate()возвращает объекты и добавляет к ним новые свойства:
>>> rez = User.objects.annotate(written_posts = Count('posts'))
>>> rez[1].written_posts
36
# у объекта класса User появилось свойство written_posts,
# хотя в модели User оно не описано Метод aggregate() отдает только значение, результат работы агрегирующей функции:
>>> Checks.objects.aggregate(average_price=Avg('price'))
{'average_price': 127.01}