
Эффективность программы можно оценить по тому, как она расходует разные типы ресурсов компьютера. Основные из них — процессорное время и оперативная память. А ещё есть пропускная способность сетевых подключений, время работы жёсткого диска и некоторые другие ограниченные ресурсы.
В первом спринте мы говорили о том, как алгоритм использует процессорное время. Теперь нас будет интересовать потребление оперативной памяти — это называется пространственной сложностью алгоритма.
Как устроена оперативная память
Оперативная память, или ОЗУ — это своего рода «черновик», который программа использует для вычислений. В него можно записывать и перезаписывать информацию, и оттуда же её можно считывать.
Современные компьютеры располагают всего несколькими гигабайтами оперативной памяти, и данные исчезают из неё сразу после завершения работы программы. Поэтому эта память не подходит для длительного хранения информации, зато она работает в сотни раз быстрее SSD и во многие тысячи раз быстрее обыкновенного жёсткого диска.
Оперативная память разбита на ячейки размером в 1 байт. У каждой ячейки есть свой порядковый номер, который называется «адрес» (отдельные биты внутри ячейки адресов не имеют). Процессор взаимодействует с оперативной памятью напрямую и использует адреса, чтобы обращаться к данным, — почти как программа обращается к переменным по имени.
Чтобы понять, сколько памяти потребляет программа, нужно выяснить, сколько места занимают отдельные объекты. В разных языках программирования этот объём памяти может отличаться, но основные принципы будут общими. Для начала мы разберём, как используется память в языке C++, так как он позволяет сделать это очень эффективно, гибко и предсказуемо.
Представление базовых типов данных в ОП
Что можно записать в одну ячейку памяти? Как мы уже говорили, размер наименьшей ячейки — 1 байт, состоящий из 8 бит. Каждый бит может принимать одно из двух значений: либо 0, либо 1. Восемь бит позволяют закодировать всего 2^8=25628=256 вариантов значений. Получается, что в такую ячейку можно записать, например, целое число в промежутке от 0 до 255.
Если считать эти числа номерами символов, то в 1 байт можно уместить 1 символ текста (тип char): все буквы латиницы и кириллицы, цифры и основные символы вполне умещаются в 256 вариантов.
Таблица кодировки описывает, какой символ соответствует каждой комбинации битов. Все современные кодировки основаны на таблице кодов ASCII, содержащей 128 символов, которые соответствуют значениям от 0 до 127.\\Многие кодировки добавляют «расшифровку» для диапазона от 128 до 255. Обычно среди них содержатся буквы национального алфавита, например, кириллица.
Более сложные кодировки используют два байта или даже переменное число байтов, чтобы закодировать разные алфавиты, иероглифы, эмодзи и множество других символов.Самый распространённый тип целых чисел int занимает 4 байта и позволяет закодировать числа от –2 147 483 648 до 2 147 483 647. Эти границы можно вычислить: в 4 байтах содержится 32 бита. Один бит тратится на то, чтобы закодировать знак. Оставшийся 31 бит позволяет закодировать 231 =2 147 483 648 чисел. Число «ноль» тоже нужно закодировать, поэтому положительных чисел остаётся на одно меньше, чем отрицательных. Если ваши числа не превышают по модулю два миллиарда, можно пользоваться этим типом чисел. Обратите внимание, что всего чисел около четырёх миллиардов, но половина из них отрицательные. Если точно известно, что переменная не может быть отрицательной, можно воспользоваться типом беззнаковых целых unsigned int, он позволяет хранить числа от 0 до 4 294 967 295.
Будьте внимательны: если в ходе вычислений получается число за пределами диапазона допустимых значений, то происходит переполнение (англ. overflow) типа, и результат вычисления может быть некорректным.
Это не относится к языкам с неограниченным размером целых чисел — таких как, например, Python.
Вещественные (то есть дробные) числа чаще всего кодируются типом double — это «числа с плавающей точкой», которые занимают 8 байт. Они могут кодировать как очень большие числа, такие как ±10308, так и близкие к нулю, например ±10−308.
Вычисления с вещественными числами чаще всего неточные и накапливают ошибку. Это может приводить к необычным эффектам. Например, из-за того, что числа хранятся в форме двоичных, а не десятичных дробей, оказывается, что 0.1×3≠0.3. Поэтому все сравнения вещественных чисел делают с учётом погрешности. Равенство из нашего примера следовало бы переписать в виде: abs(0.1 * 3 - 0.3) < EPS, где EPS — допустимая погрешность.
Если бы мы использовали вещественные числа в качестве переменной цикла, накапливающаяся неточность операций могла бы повлиять на количество итераций. Там, где важна точность и предсказуемость, вещественные числа стараются заменять целыми числами.
Иногда программе требуется запомнить адрес, то есть местоположение данных в оперативной памяти. Ещё несколько лет назад для адресации использовали 4 байта (т. е. 32 бита) — этого достаточно, чтобы адресовать 232 байт = 4 ГБ памяти. Но с тех пор мощности компьютеров и аппетиты программ выросли, четыре гигабайта памяти стали тратиться слишком быстро. Программистам пришлось перейти на 8-байтовую адресацию памяти, которой должно хватить надолго.
Составные типы данных
Теперь посчитаем, сколько памяти потребуется для хранения массива из 10 строк по 20 символов каждая.Во-первых, потребуется хранить сам текст. Это займёт
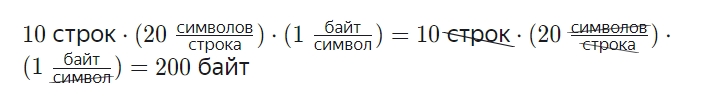
Этого было бы достаточно, если бы строки располагались в памяти друг за другом. Но производить с ними какие-либо операции будет сложно. Например, чтобы добавить символ в первую строку, нам пришлось бы сначала сдвинуть все остальные строки — как на картинке.
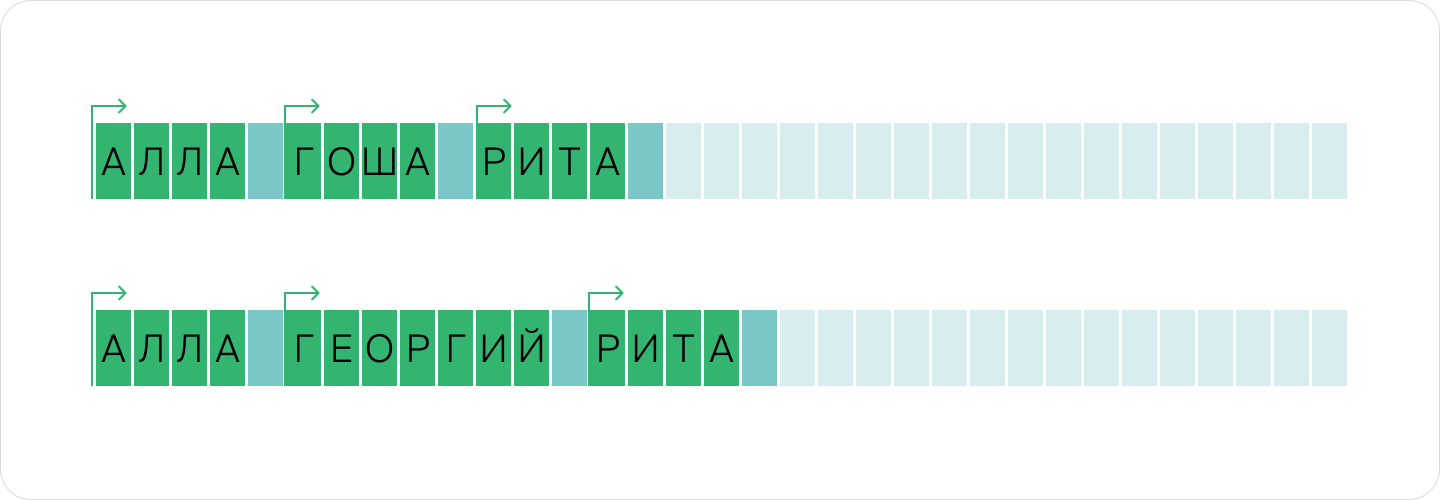
Поэтому в массивы (и в другие составные структуры) зачастую помещаются не сами объекты, а только указатели на них — адреса, по которым они хранятся в ячейках оперативной памяти.
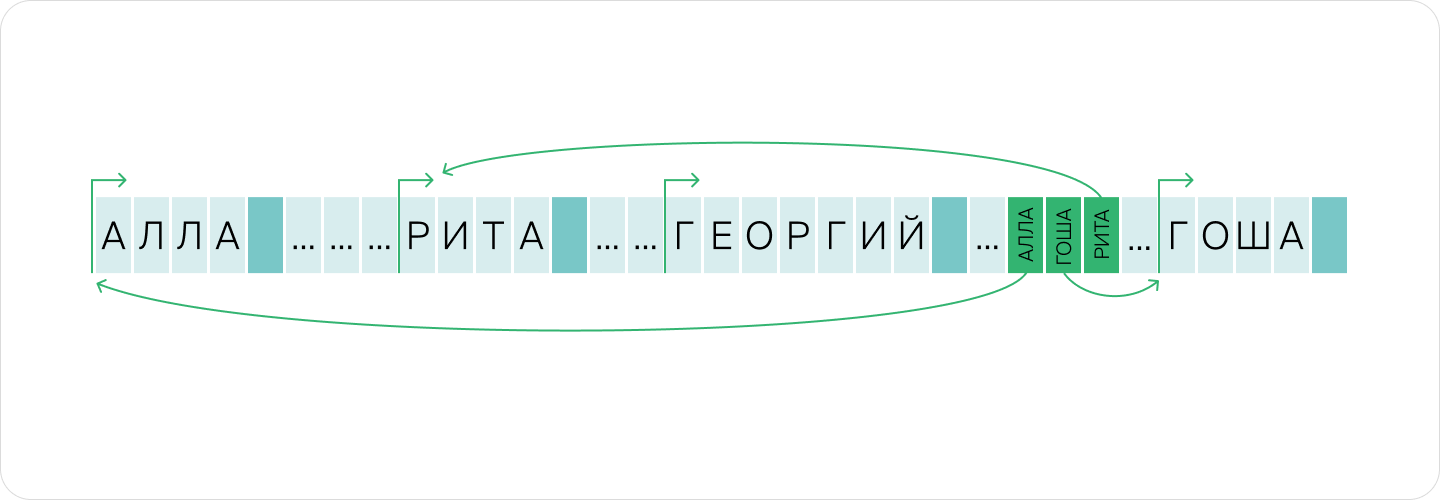
В нашем примере строки располагаются в произвольных местах памяти, а массив из десяти строк содержит лишь десять адресов, как в нижней части картинки. Получается, что массив строк занимает 200 байт на само содержимое строк + 10 адресов * 8 байт/адрес = 280 байт.
Во многих других языках каждый объект в программе записан в специальную «обёртку», которая, помимо данных, содержит вспомогательную информацию. Из-за этого, например, в языке Python даже короткие целые числа могут занимать не 4 байта, а почти 30 байт. Для хранения строки требуется около 40 байт вспомогательной информации, для хранения массива — ещё больше. Обычно объекты в таких языках ведут себя подобно строкам из предыдущего примера: они могут находиться в произвольном месте памяти, и любое обращение к ним происходит по сохранённому адресу.
Посчитаем, например, сколько памяти расходует массив из 10 чисел в Python и на что она уходит:
import sys
sys.getsizeof(42) # => 28 байт занимает короткое целое число
sys.getsizeof([]) # => 56 байт занимает пустой массив
sys.getsizeof([42]) # => 64 = (56 + 8) байт занимает массив с одним элементом.
sys.getsizeof([1,2,3,... 10]) # => 136 = (56 + 8*10) байт занимает массив
# с десятью элементами.
# сами данные хранятся отдельно
# и добавляют 280 = (28 * 10) байт Получается, мы тратим 56 байт на то, чтобы создать массив, а дальше по 8 байт на каждый новый объект в массиве — это адреса элементов. Но это ещё не всё. Ведь каждому числу нужно ещё по 28 байт. Итого массив из десяти чисел в Python занимает суммарно 56 + (8 + 28) * 10 байт = 416 байт. Сравните это с 40 байтами в языке C++.
Как освобождается память
Важно понимать, что если вы перестали пользоваться объектом, это ещё не значит, что он освободил занимаемую память. В языке C++ приходится следить за тем, чтобы выделенная память освобождалась. Встроенные контейнеры, такие как std::vector, упрощают задачу: они автоматически выделяют необходимую память при создании контейнера и освобождают её при выходе переменной контейнера из области видимости.В большинстве других языков за освобождение памяти отвечает сборщик мусора, который время от времени проверяет, может ли объект ещё быть использован. Если оказывается, что на него больше не ссылается никакая переменная и никакой другой объект, то этот объект уничтожается.
Но сборка мусора — трудоёмкая операция, поэтому некоторые языки откладывают её до тех пор, пока свободное пространство не подойдёт к концу. Например, программы на Java (если их специально не ограничить при запуске) часто сталкиваются с проблемой высокого потребления памяти из-за хранения множества старых и уже неиспользуемых объектов.